背景介绍
好久没写博客,一到周末就混过去了,本来这篇文章是要写在内网上的,想了想先发个凑合的版本出来吧,删了一些公司敏感信息。大家凑合看看思路吧。
传统模式下我们去新建一个IDC,差不多需要经过业务需求分析、网络架构设计、网络设备选型和上架配置等步骤。如今云用户越来越多,客户定制化的私有云机房需求也随之而来,面对上面一整套流程,都会因为客户的一个定制化需求而影响最终的网络。如果想要整套流程更高效,那么就需要减少我们对于架构设计和配置修改的手动操作,系统可以识别用户需求并根据需求判断合理性生成定制化方案。
如何实现上面这一套东西呢?其实从前些年来的SDN,到如今的ZTN和IBN,都在强调通过一个通用的软件接口来获取网络状态并下发相应的配置。但是这些给我的感觉始终是将部分配置抽象成自然语言或者一种图形化界面,然后根据用户选择的意图转换成复杂的配置命令下发下去,但这样并不能直接生成一套完整的网络建设方案,因为整个方案如上面所写需要硬件+配置。想要通过系统的方法建立一套网络方案,那必须对硬件和配置进行分类和抽象调用,也就是建模。
硬件建模
为了能充分对每个硬件网络设备进行通用定义和描述,我们需要对所有硬件网络设备进行建模。很早以前听过一个半吊子老司机说过,建模就是对一个事物的重复项进行分类,而厂商设计网络设备本身也是按照其物料功能进行分类的。所以我们针对不同物料根据其功能将其分为:机框、板卡、模块、风扇、电源等模型,通过物料类型字段标记每个物料的类型。针对每种物料设备我们还会录入其关联的硬件信息,比如板卡有:采购用什么型号名称、有没有采购型号不同功能完全相同的通用标示名称、板卡支持容量和速率以及板卡在设备上的采集名称等。有了每种物料的定义后我们还需要将各种物料之间的组合关系表示出来,所以有了能力模型。比如机框哪些槽位能插哪些板卡和电源,板卡哪些槽位能插哪些模块等。通过物料和能力两种模型,就可以把一个实际的网络设备表示出来了。
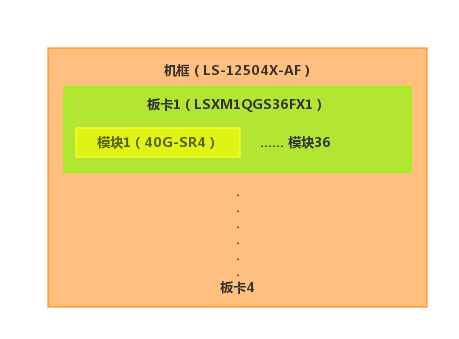
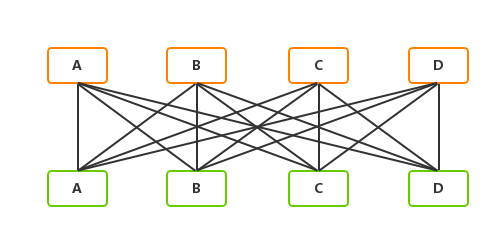
我们知道在网络拓扑中网络设备并不是独立的,而是通过光纤网线互联起来的,所以我们引入互联关系来标识不同设备之间的互联关系。两台设备之间只存在连接或者不连接两种状态,但是多台之间如何去描述连接就需要通过一些通用的连接方式去表达。
在clos数据中心架构里我们最常见的就是全互联的等分带宽,也就是两组设备之间两两互联,并且链路带宽数量一致。
配置建模
简要讲完硬件,我们来讲讲配置。我们可以发现厂商的配置命令本身就是按照各种功能来分类的,比如BGP、Interface、OSPF等,那配置命令就可以理解为是一种模型性语言,只是展示出来是命令行格式。那我直接把命令行分类不就行了,为啥还说要建模?这是因为我们网络中现在存在多种厂家设备,虽然大的类别相同,但是每家对于每种功能的命令行都不同,而且在命令逻辑上存在一定差别。Google也一直在推基于Yang格式的统一定义设备配置的Openconfig,但是在相当长的一段时间内大量设备还不支持Openconfig,所以我们还是非常需要建立一套基于CLI的通用配置模型。同时我们为了能更好的兼容openconfig的数据格式,在对各个配置参数的分类和定义上我们借鉴了Openconfig。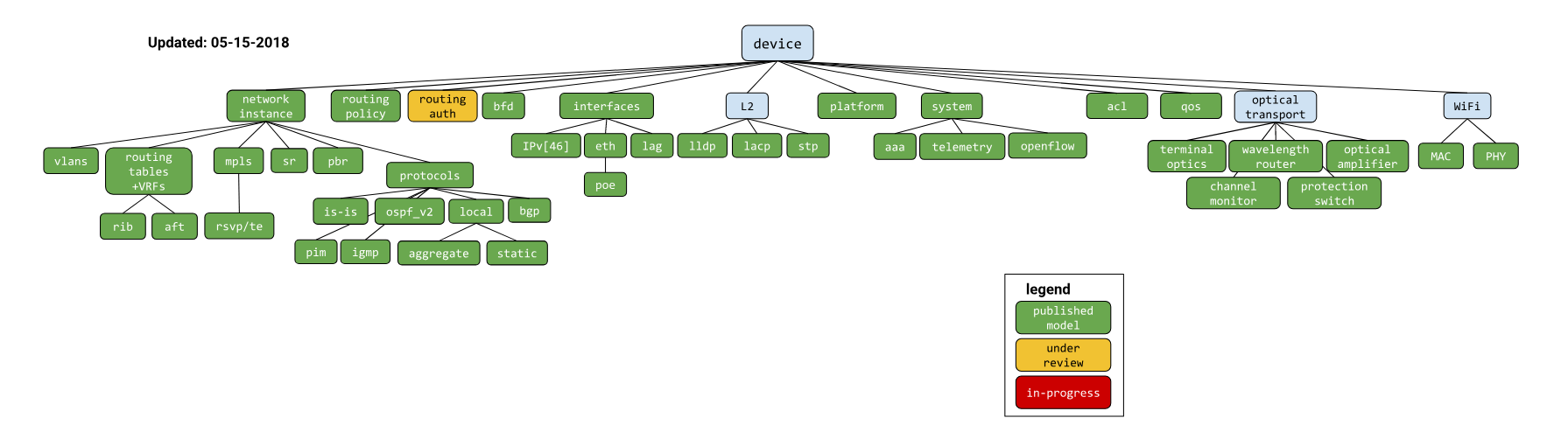
再来说下我们如何通过cli建模:
1.屏蔽厂商配置命令不同
这个很简单,就是简单的命令行分类,比如system下的hostname配置
我们通过命令模版针对不同的厂商翻译成不同的实际命令。
|
|
2. 屏蔽厂商针对某个功能配置逻辑不同
在网络配置中很多配置是需要关联其他配置的,不是可以单独配置的,比如我们配置bgp的neighbor,是需要先配置bgp的as号,address-family等命令,所以我们下发的CLI模版会针对每种功能场景进行封装,比如interfaces,bgp,ospf等,这和openconfig的定义也类似。
我们会在场景cli模版内部根据参数进行逻辑判断,对不同厂商的参数进行适配。
以aggregation口为例,我们针对每个厂商生成一组配套的cli模版
|
|
但是H3C设备针对二层的聚合口和三层的聚合口拥有不同的聚合口名称(Route-Aggregation和Bridge-Aggregation),而Opneconfig的树上并没有直接参数对此进行区分,所以我们在模版里面会判断oc-vlan:interface-mode这个参数,如果为空即既不是ACCESS也不是TRUNK,那么就是三层口。
|
|
同时不同厂商针对某个配置参数关联的OC-YANG节点可能也有所不同,还是拿interface为例。Openconfig中lacp类型定义在lacp-interfaces下的lacp-mode参数,物理接口的关联的aggregate-id是在interfaces-interface-ethernet的aggregate-id参数,但是Cisco在配置物理口的聚合组aggregate-id的时候会需要指定聚合组的LACP类型。所以我们在配置物理口的cli模版中会针对Cisco厂商传入这个lacp-mode参数。
|
|
其实聚合口模式这块的参数各家厂商的命令参数关系都有所不同,这就需要我们的模版可以兼容多种厂商逻辑差别,同时平台可以自定义前端oc-yang参数和后台模版参数的映射关系。
| OC-YANG | HW | H3C | Cisco ASR | Cisco Nexus |
| lag-type:LACP | eth-trunk:lacp-static | aggregation:link-aggregation mode dynamic | 缺省 | 缺省 |
| lag-type:STATIC | eth-trunk:manual | 缺省 | ethernet、bundle:lacp mode on | ethernet:port-channel x mode on |
| lacp-mode:ACTIVE | 缺省 | 缺省 | ethernet、bundle:lacp mode active | ethernet:port-channel x mode active |
| lacp-mode:PASSIVE | 无 | aggregation:lacp mode passive | ethernet、bundle:lacp mode passive | ethernet:port-channel x mode passive |
通过上面的介绍就可以覆盖所有的openconfig所定义参数的配置场景。针对openconfig中未定义的部分,我们会根据设备cli提取所需的参数来补充模型,从而全面支撑我们网络的配置模型建立。
比如openconfig针对acl只通过acl_name来指定acl实例,但是我们知道HW/H3C和早期的Cisco是通过acl_number来指定acl实例的,同时这些设备也可以指定acl_name,所以我们不能简单地把oc-yang的acl_name直接映射成cli的acl_number
|
|
通过上面的cli我们还可以看到H3C/HW的acl里面是支持vrf的,但是oc-yang里面也没有指定。这块通用的逻辑是acl本身只是匹配地址规则,不判断地址所在的网络实例,比如在接口interface上调用acl,interface本身是关联vrf网络实例的,所以acl本身不应该配置vrf。那为什么H3C/HW需要在acl里面指定vrf呢,做了一些实验发现,HW/H3C如果不带vrf在接口下acl会匹配所有vrf,但是如果在诸如snmp、ssh之类的特性下调用acl就必须带vrf,否则会匹配不上来自非全局vrf下的流量。

可以看出即便一个非常简单的feature在做多厂商建模时也要充分考虑每种厂商对于该特性的处理逻辑,想要完全屏蔽厂商差异就必须全面覆盖所有可能性的同时找出其内部逻辑关联。
配置+硬件
上面介绍了配置和硬件建模的基础实现逻辑,接下来是通过调用两者,来对我们的网络架构进行抽象定义。在每个架构中,我们会以网元为单位,抽象每个层级的设备,通常以其功能名称和ID来标记网元。以一个简单架构为例,规划设计内网接入设备(TOR)88台、内网核心设备(CORE)4台,可以标识为TOR1-TOR88,CORE1-CORE4。
首先设计一个逻辑的CORE的硬件模型所有接口全部用于和TOR互联,如下图
再设计一个逻辑的TOR硬件模型,假设只需要接入16台服务器,如下图
接下来我们调用硬件模型的互联关系,选择等分带宽全互联,即可生成一个满配的连接实例。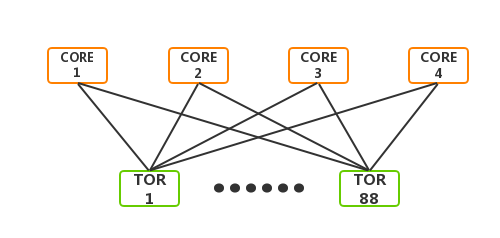
接下来我们会对每个逻辑设备进行实际硬件映射,理论上只需要支持20端口*4板卡以上的设备就可以当CORE,TOR也是一样需要支持4个上联口和16个下联口即可。当我们将所有符合上述要求的硬件设备和逻辑设备映射完成后,在每次需求下发时,系统会自动根据所需服务器数量、服务器网卡类型以及TOR上联收敛比等需求自动计算出实际对应的设备型号和物料数量。
比如需要10G网卡的服务器500台,TOR上联收敛比是1:1,那么就会录入的硬件模型匹配出采购32台TOR(40G*4上联,10G*48下联的交换机),和4台CORE(40G*36口*2板卡的交换机)。
在生成了设备连接和物料信息之后就是配置的生成。同样,我们会根据每种网元定义其配置模版。
我们会结合之前的配置属性树来选择配置项,并为期设置赋值方法。
比如TOR都会有system的配置,我会选择需要配置的参数并为其赋值
|
|
同时我们可以引用通过硬件模型生成连接后的数据对接口其进行定义,如下图对CORE连接物理口定义description
|
|
最终配置会根据实际项目去判断是自营机房还是云机房进行不同的参数赋值,同时会根据实际的连接关系生成完整的接口和路由配置。
上面只是介绍了网络方案通过配置和硬件建模实现的基础逻辑,实际的网络方案可能远比上面复杂很多,生成的逻辑算法也会更复杂,比如硬件会考虑未来可扩容的需求,配置上需要根据网络规模的不同选用不同的网络路由协议,对网络参数进行不同的赋值等等。
如果你也对网络建模和自动化网络建设感兴趣欢迎与我交流,也欢迎成为同事。
